
A Look At Champ Mentions in the League of Legends Subreddit
I wanted to percieve the popularity of champions in the League of Legends subreddit. First, I decided to carry out a simple frequency based approach.
import praw
reddit = praw.Reddit(client_id='****************',
client_secret='**********',
user_agent='**************',
username='***********',
password='*********')
Having initialized the Reddit instance using PRAW( The Python Reddit API Wrapper), I should now open the League of Legends subreddit (r/leagueoflegends). After that, I’ll collect the top 500 posts for the past month and all off the sub comments. I’ve decided to only go 5 layers deep into the comments to make computations faster.
subreddit = reddit.subreddit('leagueoflegends')
file = open('lol_dump.txt', 'w+')
for i in subreddit.top(time_filter = 'month', limit = 500):
try:
file.write(i.title)
except:
n = 1
i.comments.replace_more(limit=5)
comment_queue = i.comments[:] # Seed with top-level
while comment_queue:
comment = comment_queue.pop(0)
try:
file.write(comment.body.lower())
file.write('\n')
except:
n = 1
comment_queue.extend(comment.replies)
file.close()
Now, I’ll scrape all of the names of the different champions and make a list.
import bs4
import requests
url = "https://app.mobalytics.gg/champions"
page = requests.get(url)
soup = bs4.BeautifulSoup(page.content, 'lxml')
raw = soup.find_all(name='div', attrs={'class':'champion-infostyles__ChampionName-sc-13d2o0k-1 gJhcAt'})
t = []
for i in raw:
t.append(i.text.lower())
I should probably add common alternatives used for certain champs. For example, a lot of people will just write Velkoz or Nunu instead of Vel’Koz and Nunu and Willump respectively. I’ll even include MF although that might have quite a bit of noise. Also, since this is a word by word search, for champions with names longer than one word, I’ll also introduce one word terms used to refer to them. After adding the nicknames to the list of champions, I’ll create a dictionary using this list’s elements as keys.
nicks = ['aurelion','velkoz', 'nunu', 'aurelion', 'a-sol', 'blitz', 'chogath', 'mundo', 'gp', 'jarvan', 'khazix', 'kaisa', 'shyv',
'kogmaw', 'kog', 'fiddle', 'reksai', 'mf', 'morde', 'heimer', 'cait', 'cassio', 'tf', 'tahm', 'trist', 'xin', 'fortune',
'yi', 'lee', 'twisted', 'tris', 'kha', 'vlad']
for i in nicks:
t.append(i)
t.sort()
s = {}
for i in t:
s[i] = 0
Now I just need to run a simple search through the aggregated titles and comments.
# load text
file = open('lol_dump.txt', 'r+')
text = file.read()
file.close()
# split into words by white space
words = text.split()
# remove punctuation from each word
import string
table = str.maketrans('', '', string.punctuation)
stripped = [w.translate(table) for w in words]
file = open('lol_dump.txt', 'r+')
for i in stripped:
if(i in t):
s[i]+=1
k = 0
for i in range(len(stripped)):
if(stripped[i]== 'tf' and stripped[i+1]=='blade'):
k+=1
Now let’s add the nickname ones to their actual names.
s['xin zhao'] = s['xin'] + s['xin zhao']
s['aurelion sol'] = s['aurelion'] + s['a-sol']
s['miss fortune'] = s['mf'] + s['fortune']
s['nunu & willump'] = s['nunu']
s['dr. mundo'] = s['mundo']
s["vel'koz"] = s['velkoz'] + s["vel'koz"]
s["kha'zix"] = s['khazix'] + s["kha'zix"] + s['kha']
s["kai'sa"] = s['kaisa'] + s["kai'sa"]
s["rek'sai"] = s["rek'sai"] + s['reksai']
s["cho'gath"] = s["cho'gath"] + s['chogath']
s["kog'maw"] = s["kog'maw"] + s["kogmaw"] + s["kog"]
s['heimerdinger'] = s['heimer'] + s['heimerdinger']
s['cassiopeia'] = s['cassiopeia'] + s['cassio']
s['gangplank'] = s['gangplank'] + s['gp']
s['blitzcrank'] = s['blitz'] + s['blitzcrank']
s['caitlyn'] = s['cait'] + s['caitlyn']
s['fiddlesticks'] = s['fiddle'] + s['fiddlesticks']
s['tristana'] = s['trist'] + s['tris'] + s['tristana']
s['jarvan iv'] = s['jarvan']
s['shyvana'] = s['shyvana'] + s['shyv']
s['mordekaiser'] = s['mordekaiser'] = s['morde']
s['twisted fate'] = s['twisted'] + s['tf'] -225
s['master yi'] = s['yi']
s['tahm kench'] = s['tahm']
s['lee sin'] = s['lee']
s['vladimir'] += s['vlad']
Now delete the nicknames from the list.
for i in nicks:
t.remove(i)
y = []
w = {}
for i in t:
y.append(s[i])
w[i] = s[i]
l = {k: v for k, v in sorted(w.items(), key=lambda item: item[1])}
a = []
b = []
for i in l:
a.append(i)
b.append(l[i])
import matplotlib.pyplot as plt; plt.rcdefaults()
import numpy as np
import matplotlib.pyplot as plt
#plt.rcParams['font.family'] = 'sans-serif'
#plt.rcParams['font.sans-serif'] = 'Helvetica'
plt.style.use('ggplot')
plt.rcParams['axes.edgecolor']='#333F4B'
plt.rcParams['axes.linewidth']=0.8
plt.rcParams['xtick.color']='#333F4B'
plt.rcParams['ytick.color']='#333F4B'
plt.figure(figsize = (10, 30), facecolor = None)
plt.barh(t, y, align='center', alpha=0.5)
plt.yticks(t)
plt.xlabel('Frequency')
plt.title('League Champion Popularity in Top 500 posts for the past month and comments(upto 5 layers)')
for index, value in enumerate(y):
plt.text(value, index, str(value))
plt.savefig("Champ_freq.jpg")
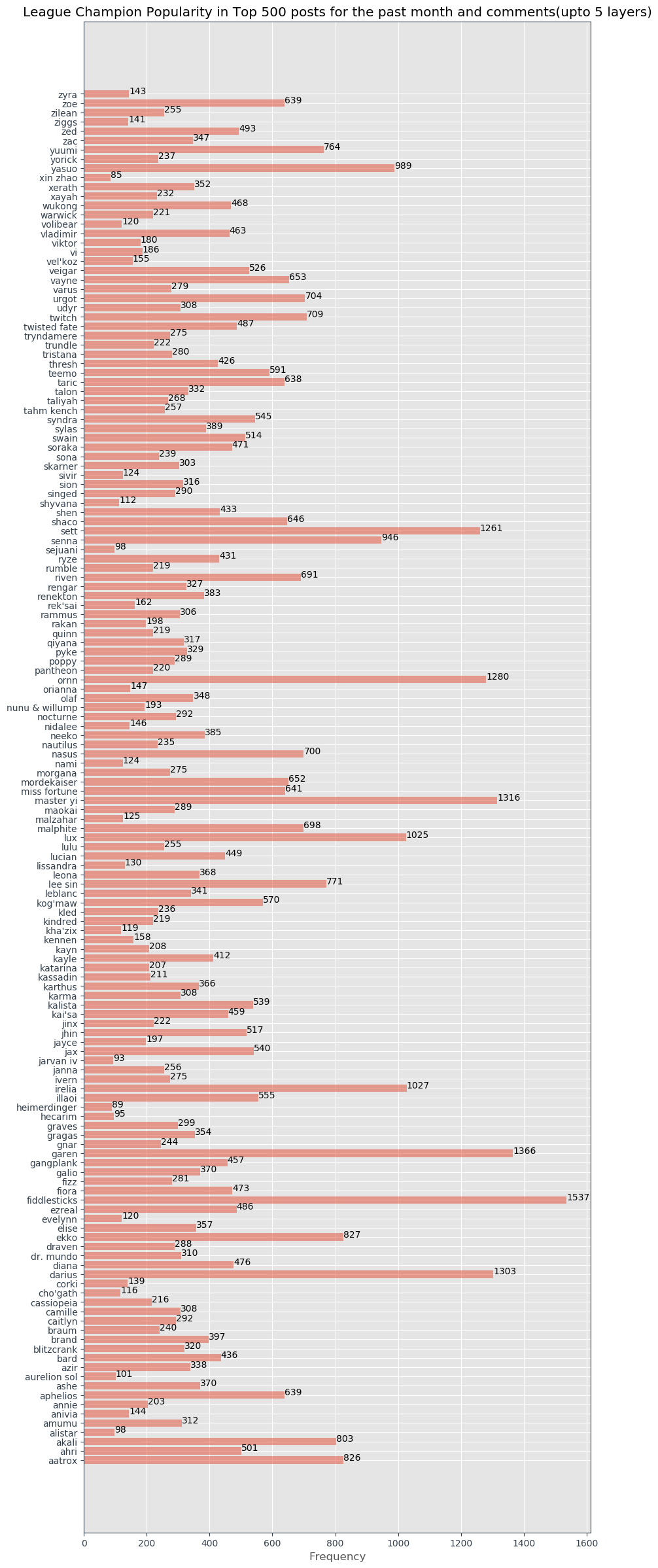
Let’s do a quick comparison of these percentages with pick/ban rates across different tiers. I got the respective pick ban rates accross all tiers from op.gg as it was the most hassle free method I found. I will also scale the Mention ratio appropriately so that I can have them all on one graph.
import pandas as pd
df = pd.read_csv(r"C:\Users\APOORV\Downloads\Untitled spreadsheet - Sheet3.csv")
v = 0
for i in y:
v+=i
l = []
for i in y:
l.append(1000*i/v)
df['Mention Ratio'] = l
df.head()
| Champ | Pick Ratio | Ban Ratio | Mention Ratio | |
|---|---|---|---|---|
| 0 | Aatrox | 6.20 | 4.33 | 13.856038 |
| 1 | Ahri | 7.28 | 3.20 | 8.404207 |
| 2 | Akali | 3.51 | 4.28 | 13.470216 |
| 3 | Alistar | 3.50 | 0.66 | 1.643937 |
| 4 | Amumu | 6.62 | 1.53 | 5.233758 |
plt.style.use('ggplot')
plt.rcParams['axes.edgecolor']='#333F4B'
plt.rcParams['axes.linewidth']=2
plt.rcParams['xtick.color']='#333F4B'
plt.rcParams['ytick.color']='#333F4B'
plt.figure(figsize = (70, 30), facecolor = None)
plt.xticks(rotation=90)
plt.plot( 'Champ', 'Pick Ratio', data=df, marker='o', markerfacecolor='blue', markersize=12, color='skyblue', linewidth=4)
plt.plot( 'Champ', 'Ban Ratio', data=df, marker='', color='olive', linewidth=2)
plt.plot( 'Champ', 'Mention Ratio', data=df, marker='', color='olive', linewidth=2, linestyle='dashed', label="toto")
plt.legend()
<matplotlib.legend.Legend at 0x21ac569e5f8>

Now, let’s conduct try to see if they are correlated.
df.corr()
| Pick Ratio | Ban Ratio | Mention Ratio | |
|---|---|---|---|
| Pick Ratio | 1.000000 | 0.591431 | 0.463995 |
| Ban Ratio | 0.591431 | 1.000000 | 0.541957 |
| Mention Ratio | 0.463995 | 0.541957 | 1.000000 |
It doesn’t look like there’s a very strong correlation between them. Maybe that’s because of the Fiddlesticks rework? Let’s remove it and try again.
df = df.drop(28)
df.corr()
| Pick Ratio | Ban Ratio | Mention Ratio | |
|---|---|---|---|
| Pick Ratio | 1.000000 | 0.590327 | 0.517298 |
| Ban Ratio | 0.590327 | 1.000000 | 0.590476 |
| Mention Ratio | 0.517298 | 0.590476 | 1.000000 |
That improved both the Pick-Mention and Ban-Mention correlations!. Nice!
```