
Battle of the Sexes: Subreddit Edition
I was browsing through Reddit the other day and I started to wonder if there was a significant way in which the contents of the r/AskMen and r/AskWomen subreddits differed. Like the names suggest, the purpose of the subreddits are to ask people of a specific gender questions about their views and experiences with regards to some topics. I scraped the top 1000 posts and upto 15 layers of comment for those posts using PRAW (Python Reddit API Wrapper).
Loading in Data and PreProcessing
AskMen <- read.csv("AskMen.csv")
AskWomen <- read.csv("AskWomen.csv")
AskMen$Text <- tolower(str_replace_all(str_conv(AskMen$Text, 'UTF8'), "_", ""))
AskWomen$Text <- tolower(str_replace_all(str_conv(AskWomen$Text, 'UTF8'), "_", ""))
Title Analysis
I decided to investigate word co-ocurrences and correlations in post
titles by making a word network of the contents of the titles of each
post to try and get some sense of common themes in posts and connections
within them. I used pairwise_count() from the widyr package to count
how many times each pair of words occurs together in a title or
description field.
Men
AskMenTitles <- read.csv("AskMenTitles.csv")
AskWomenTitles <- read.csv("AskWomenTitles.csv")
e <- tibble(id = as.character(AskMenTitles$X), title = str_conv(AskMenTitles$Text, 'UTF8'))
e <- e %>%
unnest_tokens(word, title) %>%
anti_join(stop_words)
## Joining, by = "word"
men_word_pairs <- e %>% pairwise_count(word, id, sort = TRUE, upper = FALSE)
set.seed(1234)
men_word_pairs %>%
filter(n > 2) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "blue") +
geom_node_point(size = 5) +
geom_node_text(aes(label = name), repel = TRUE,
point.padding = unit(0.2, "lines")) +
theme_void()
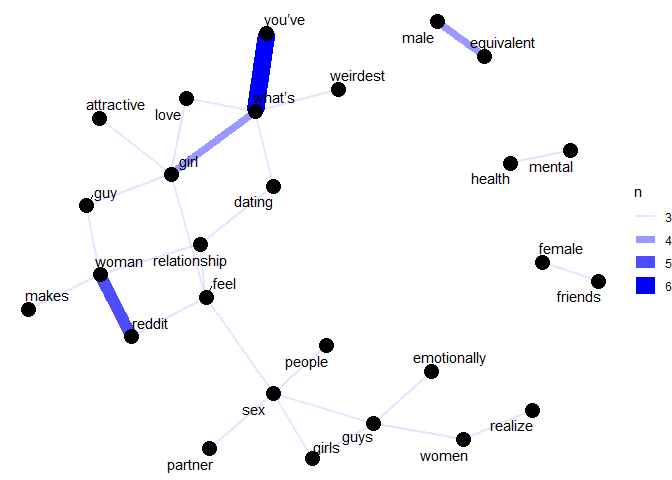
Women
e <- tibble(id = as.character(AskWomenTitles$X), title = str_conv(AskWomenTitles$Text, 'UTF8'))
e <- e %>%
unnest_tokens(word, title) %>%
anti_join(stop_words)
## Joining, by = "word"
women_word_pairs <- e %>% pairwise_count(word, id, sort = TRUE, upper = FALSE)
set.seed(1234)
women_word_pairs %>%
filter(n > 2) %>%
graph_from_data_frame() %>%
ggraph(layout = "fr") +
geom_edge_link(aes(edge_alpha = n, edge_width = n), edge_colour = "pink") +
geom_node_point(size = 5) +
geom_node_text(aes(label = name), repel = TRUE,
point.padding = unit(0.2, "lines")) +
theme_void()
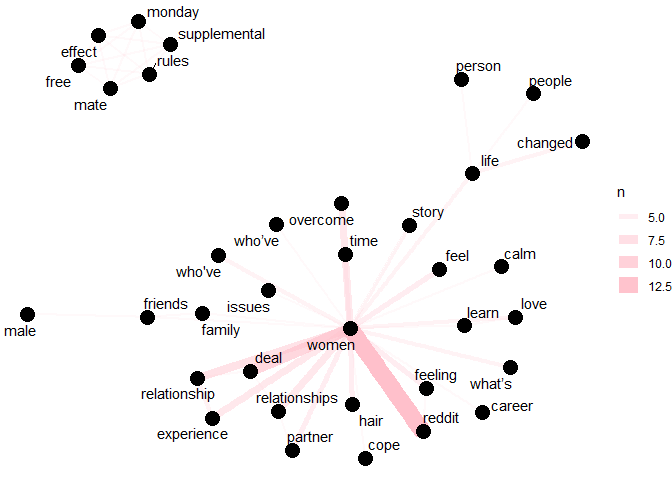
Comment Analysis
I used unnest_tokens() to make a tidy data frame of all the words in
each of the corpuses from r/AskMen and r/AskWomen. I also filtered out
some common stop words.
s <- tibble('txt' = AskMen$Text)
t <- tibble('txt' = AskWomen$Text)
MenTokens <- s %>% unnest_tokens(word, txt) %>%
filter(!word %in% stop_words$word,
!word %in% str_remove_all(stop_words$word, "'"),
str_detect(word, "[a-z]"))
WomenTokens <- t %>% unnest_tokens(word, txt)%>%
filter(!word %in% stop_words$word,
!word %in% str_remove_all(stop_words$word, "'"),
str_detect(word, "[a-z]"))
Next, I calculated word frequencies for each subreddit. First, I grouped by subreddit and counted the number of times the word was used in the comments of the specific sub reddit.
tidy_coms <- bind_rows(MenTokens %>% mutate(sub = "AskMen"),
WomenTokens %>% mutate(sub = "AskWomen"))
tidy_coms <- tidy_coms %>% group_by(sub) %>%
count(word, sort = TRUE) %>%
left_join(tidy_coms %>% group_by(sub) %>%
summarise(total = n())) %>%
mutate(freq = n/total)
## Joining, by = "sub"
I tried to gauge word usage with a simple scatter plot taking the individual counts as coordinates.
com_total <- tidy_coms %>% select(sub, word, n) %>%
spread(sub, n) %>%
arrange(AskMen, AskWomen)
ggplot(com_total, aes(AskMen, AskWomen))+
geom_jitter(alpha = 0.01, size = 2.5, width = 0.25, height = 0.25) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5)
## Warning: Removed 38238 rows containing missing values (geom_point).
## Warning: Removed 38238 rows containing missing values (geom_text).
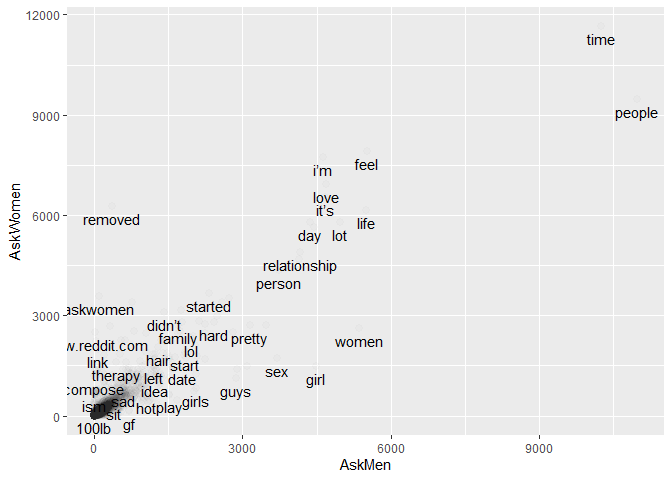 This doesn’t really give much of a feel. So I decided to use the
frequencies of the words instead.
This doesn’t really give much of a feel. So I decided to use the
frequencies of the words instead.
com_freq <- tidy_coms %>% select(sub, word, freq) %>%
spread(sub, freq) %>%
arrange(AskMen, AskWomen)
ggplot(com_freq, aes(AskMen, AskWomen)) +
geom_jitter(alpha = 0.01, size = 2.5, width = 0.25, height = 0.25) +
geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
geom_abline(color = "red")
## Warning: Removed 38238 rows containing missing values (geom_point).
## Warning: Removed 38238 rows containing missing values (geom_text).
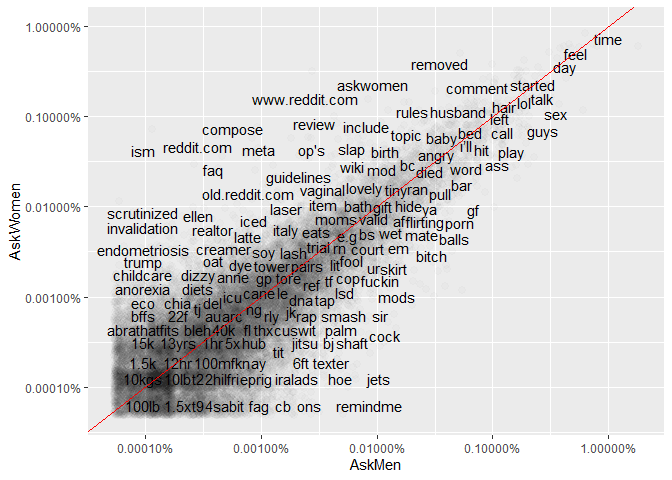
While most words seem to be similarly used, some words are interestingly skewed towards conforming with traditional gender roles such as sports for men and birthing for women.
Sentiment Analysis of Comments
A sentiment analysis of the comments from the two subreddits would be pretty interesting.
y<- AskMen %>%
group_by(X) %>%
ungroup() %>%
unnest_tokens(word, Text)
x<- AskWomen %>%
group_by(X) %>%
ungroup() %>%
unnest_tokens(word, Text)
yy<- y %>%
inner_join(get_sentiments("bing")) %>%
count(index = X %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
## Joining, by = "word"
xx<- x %>%
inner_join(get_sentiments("bing")) %>%
count(index = X %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
## Joining, by = "word"
men_sentiment <- ggplot(yy, aes(index, sentiment)) +
geom_col(show.legend = FALSE)
women_sentiment <- ggplot(xx, aes(index, sentiment)) +
geom_col(show.legend = FALSE)
ggarrange(men_sentiment, women_sentiment, ncol = 2, labels = c("r/AskMen", "r/AskWomen"))
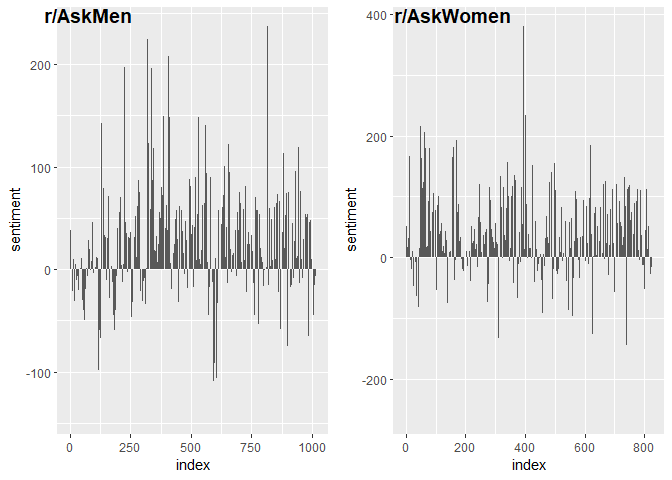 Looks like r/AskMen has more wholesome content as compared to
r/AskWomen in general but the hate comes on pretty strong when it does come out. Let’s take a look at the most common positive words once.
Looks like r/AskMen has more wholesome content as compared to
r/AskWomen in general but the hate comes on pretty strong when it does come out. Let’s take a look at the most common positive words once.
bing_word_counts_y <- y %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()
## Joining, by = "word"
bing_word_counts_x <- x %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()
## Joining, by = "word"
men<- bing_word_counts_y %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()
## Selecting by n
wim<- bing_word_counts_x %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()
## Selecting by n
ggarrange(men, wim, nrow = 2, labels = c("r/AskMen", "r/AskWomen"))
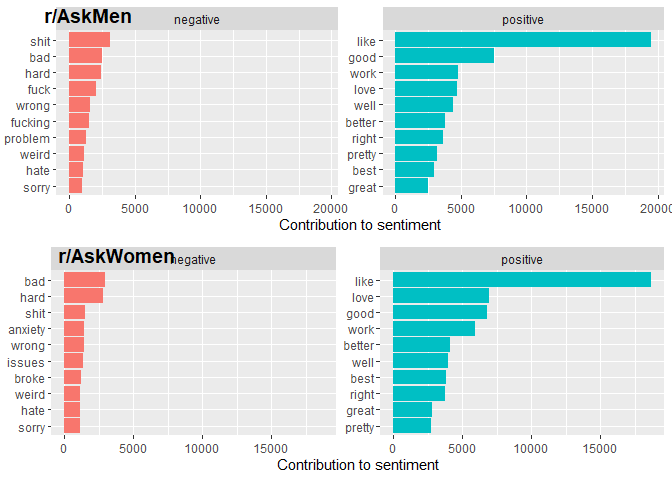
Like and well probably have a lot of noise from being used in other ways.