
Harvard Business Review Interactive Wordcloud
The Harvard Business Review is one of the most presitigious general management magazines in the world with a circulation of over 250,000 over a span of 14 languages. It is a regular source of excellent insights in a litany of domains like strategy, negotiation, and operations. They often cover trendsetting practices that have the potential to change industries. I thought it would be a fun exercise to take a look at recent trends of word usage in their articles.
Scraping Data I scraped articles from 2012 through 2019 using the
good old BeautifulSoup library in Python and utilized the NLTK module for text processing to generate word tokens and remove stopwords. You can refer to the scraper in detail here
full <- read.csv("HBR data.csv")
#artlist <- read.csv("HBR Article Listing.csv")
full$word<-as.character(full$word)
full$Article.text<-as.character(full$Article.text)
full$Title.text <- as.character(full$Title.text)
df <- subset(full, select = c(word, Title.counts) )
Interactive WordCloud
I decided on an interactive wordcloud as my medium of expression. We’ll
introduce the ability to filter input and output corpuses on the basis
of whether they’re words from titles or from article bodies. You can
also filter the output to be either Titles or sentences containing those
words in various article bodies.
Let’s also add a lineplot to observe how the usage of the word has
varied over the years in the selected output categories. We’ll be
building the wordcloud using the wordlcoud2 package.
WordCloud Interactivity function
I wrote a little function that allows us to take inputs as the word clicked on in the wordcloud and then outputs our desired text.
wc2ClickedWord = function(cloudOutputId, inputId) {
#ARGUMENTS
# - cloudOutputId: string; outputId of wordcloud2 obj being rendered (should be identical to the value passed to wordcloud2Output)
# - inputId: string; inputId of word clicked on (ie you will reference in server the word by input$inputId)
#OUPUT
# - referencing input in server will return a string of form word:freq (same as hover info shown in wordcloud; ie 'super:32')
tags$script(HTML(
sprintf("$(document).on('click', '#%s', function() {", cloudOutputId),
'word = document.getElementById("wcSpan").innerHTML;',
sprintf("Shiny.onInputChange('%s', word);", inputId),
"});"
))
}
Shiny App
Since we want an element of interactivity, we should naturally use the shiny package in R to build an app. Since the app is interactive, I can’t embed it here. Here’s a screenshot of the app and you can check it out over here
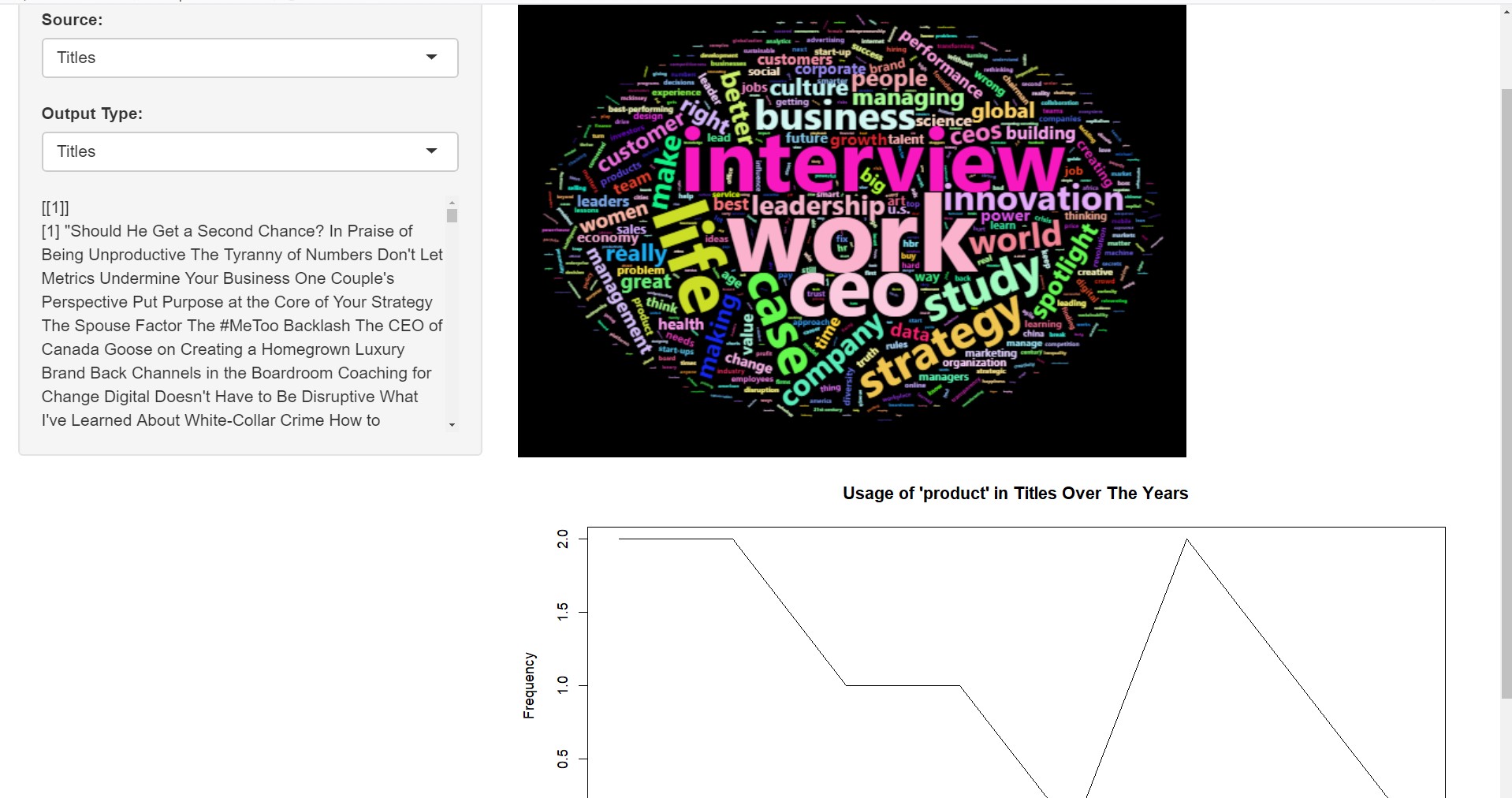
Code:
library(shiny)
library(wordcloud2)
shinyApp(
ui=shinyUI(fluidPage(
wc2ClickedWord("my_wc", "selected_word"),
# Application title
titlePanel("Harvard Business Review: WordCloud"),
sidebarLayout(
sidebarPanel(
selectInput("variable", "Source:",
c("Titles" = "Title.counts",
"Article Text" = "Article.counts")),
selectInput("out", "Output Type:",
c("Titles" = "Title.text",
"Article Text" = "Article.text")),
# sliderInput("range", "Range:",
# min = 2012, max = 2019,
# value = c(2012,2019)),
textOutput("print"),
textOutput("printt"),
tags$style(type="text/css", "#print {white-space: pre-wrap;overflow-y:scroll; max-height: 200px;}")
),
# Show a plot of the generated wordcloud
mainPanel(
wordcloud2Output("my_wc"),
plotOutput("barplot")
)
)
)),
server=shinyServer(function(input,output,session){
output$my_wc = renderWordcloud2({
if(input$variable == "Title.counts") df <- subset(full, select = c(word, Title.counts) )
else df <- subset(full, select = c(word, Article.counts) )
wordcloud2(df, size = 0.5, minSize = 0, gridSize = 0,fontFamily ='Segoe UI',
fontWeight ='bold',color ='random-light', backgroundColor = "black",
minRotation = -pi/2, maxRotation = pi/2, shuffle = TRUE,rotateRatio = 0.4,
shape ='circle', ellipticity = 0.65,widgetsize = NULL, figPath = NULL,
hoverFunction = NULL)
})
output$print = renderPrint({
if(input$out == "Title.text"){
f <- subset(full, select = c(word, Title.text) )
strsplit(f[f$word==gsub("\\:.*","", as.character(input$selected_word)),]$Title.text, "\n")
}
else{
f <- subset(full, select = c(word, Article.text) )
strsplit(f[f$word==gsub("\\:.*","", as.character(input$selected_word)),]$Article.text, "\n")
}
}
)
output$barplot <- renderPlot({
if(input$out == "Title.text"){
tmpdf <- as.data.frame(as.numeric(unlist(strsplit(
gsub('[[:punct:] ]+',' ', full[full$word==gsub("\\:.*","", as.character(input$selected_word)),]$usage.in.titles), ' '))[2:9]))
years <- as.data.frame(2012:2019)
s <- cbind(years, tmpdf)
colnames(s)<- c("years", "counts")
w <- gsub("\\:.*","", as.character(input$selected_word))
w<- paste(c("Usage of '"), w, c("' in Titles Over The Years"), sep = '')
plot(s$years,s$counts, 'l', xlab = c("Years"), ylab = c("Frequency"), main = w)
}
else{
tmpdf <- data.frame(as.numeric(unlist(strsplit(
gsub('[[:punct:] ]+',' ', full[full$word==gsub("\\:.*","", as.character(input$selected_word)),]$usage.in.articles), ' '))[2:9]))
years <- as.data.frame(2012:2019)
s <- cbind(years, tmpdf)
colnames(s)<- c("years", "counts")
w <- gsub("\\:.*","", as.character(input$selected_word))
w<- paste(c("Usage of '"), w, c("' in Articles Over The Years"), sep = '')
plot(s$years,s$counts, 'l', xlab = c("Years"), ylab = c("Frequency"), main = w)
}
})
}),
options = list(height = 1000)
)