
Modi vs RaGa:Twitter Edition
I recently read a great article by David Robinson (I highly recommend his blog for some fun reading) and started wondering about how the tweets of our country’s biggest political bigwigs differ from each other. I scraped their tweets using the GetOldTweets3 library in python which conveniently let me retrieve their recent tweets.
Load Data
Let’s quickly load up our data and combine the two tables to form one table.
modi <- suppressMessages(readr::read_csv("F:/Playin/Pol/Modi.csv"))
## Warning: Missing column names filled in: 'X1' [1]
raga <- suppressMessages(readr::read_csv("F:/Playin/Pol/Raga.csv"))
## Warning: Missing column names filled in: 'X1' [1]
library(dplyr)
##
## Attaching package: 'dplyr'
## The following objects are masked from 'package:stats':
##
## filter, lag
## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, union
modi <- modi %>% mutate("Person" = "Modi")
raga <- raga %>% mutate("Person" = "Rahul Gandhi")
data <- rbind(modi, raga)
str(data)
## tibble [4,250 x 5] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## $ X1 : num [1:4250] 0 1 2 3 4 5 6 7 8 9 ...
## $ tweet : chr [1:4250] "NDRF teams are working in the cyclone affected parts. Top officials are closely monitoring the situation and al"| __truncated__ "Have been seeing visuals from West Bengal on the devastation caused by Cyclone Amphan. In this challenging hour"| __truncated__ "My thoughts are with the people of Odisha as the state bravely battles the effects of Cyclone Amphan. Authoriti"| __truncated__ "On his death anniversary, tributes to former PM Shri Rajiv Gandhi." ...
## $ lang : chr [1:4250] "en" "en" "en" "en" ...
## $ time : POSIXct[1:4250], format: "2020-05-21 08:20:37" "2020-05-21 08:20:08" ...
## $ Person: chr [1:4250] "Modi" "Modi" "Modi" "Modi" ...
Data Exploration
Time of Tweet
Let’s look at the time of their tweets and see if there are any patterns there?
library(lubridate)
##
## Attaching package: 'lubridate'
## The following objects are masked from 'package:dplyr':
##
## intersect, setdiff, union
## The following objects are masked from 'package:base':
##
## date, intersect, setdiff, union
library(ggplot2)
t <- strftime(data$time, format="%H:%M:%S")
data$time <- as.POSIXct(t, format="%H:%M:%S")
ggplot(data = data, aes(x = X1, y = time, color = Person)) +
geom_point(alpha = 0.2)
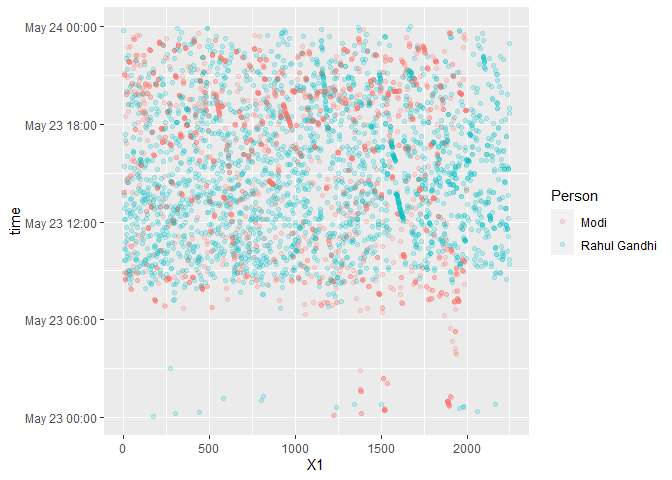 Ignore the date in the plot, that’s just from stripping the date element
from the tweets to get the time and then adding an identical date so we
can plot out the tweets with respect to time of the day. Looks like Modi
tweets a little later at night as compared to Rahul Gandhi. Let’s verify
using a boxplot.
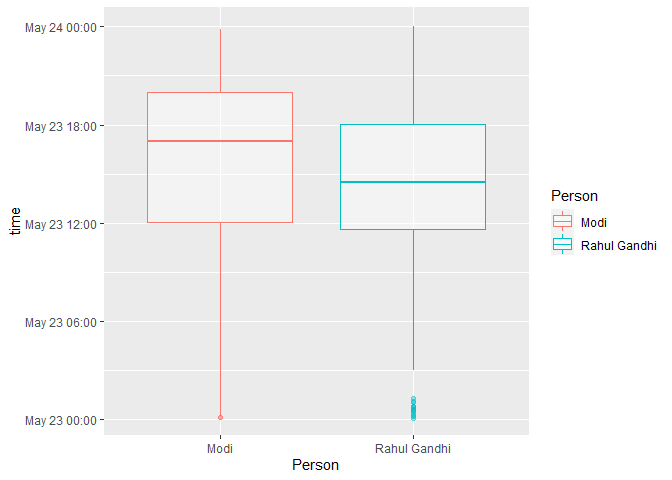
Ignore the date in the plot, that’s just from stripping the date element
from the tweets to get the time and then adding an identical date so we
can plot out the tweets with respect to time of the day. Looks like Modi
tweets a little later at night as compared to Rahul Gandhi. Let’s verify
using a boxplot.
ggplot(data = data, aes(x = Person,y = time, color = Person)) +
geom_boxplot(alpha = 0.4)
Sentiment Analysis
Let’s do a sentiment analysis of the English tweets of the two men. We’ll use the bing lexicon to gauge positivity and negativity.
library(tidytext)
library(tidyr)
modi_sent<-modi %>%
select(c("X1","tweet")) %>%
group_by(X1) %>%
unnest_tokens(word, tweet)%>%
inner_join(get_sentiments("bing")) %>%
count(index = X1 %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
## Joining, by = "word"
raga_sent<-raga %>%
select(c("X1","tweet"))%>%
group_by(X1) %>%
unnest_tokens(word, tweet)%>%
inner_join(get_sentiments("bing")) %>%
count(index = X1 %/% 80, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
## Joining, by = "word"
Let’s draw up plots of the net sentiments of their tweets.
library(ggpubr)
modi_senti <- ggplot(modi_sent, aes(index, sentiment)) +
geom_col(show.legend = FALSE)
raga_senti <- ggplot(raga_sent, aes(index, sentiment)) +
geom_col(show.legend = FALSE)
ggarrange(modi_senti, raga_senti, ncol = 2, labels = c("Modi", "Rahul Gandhi"))
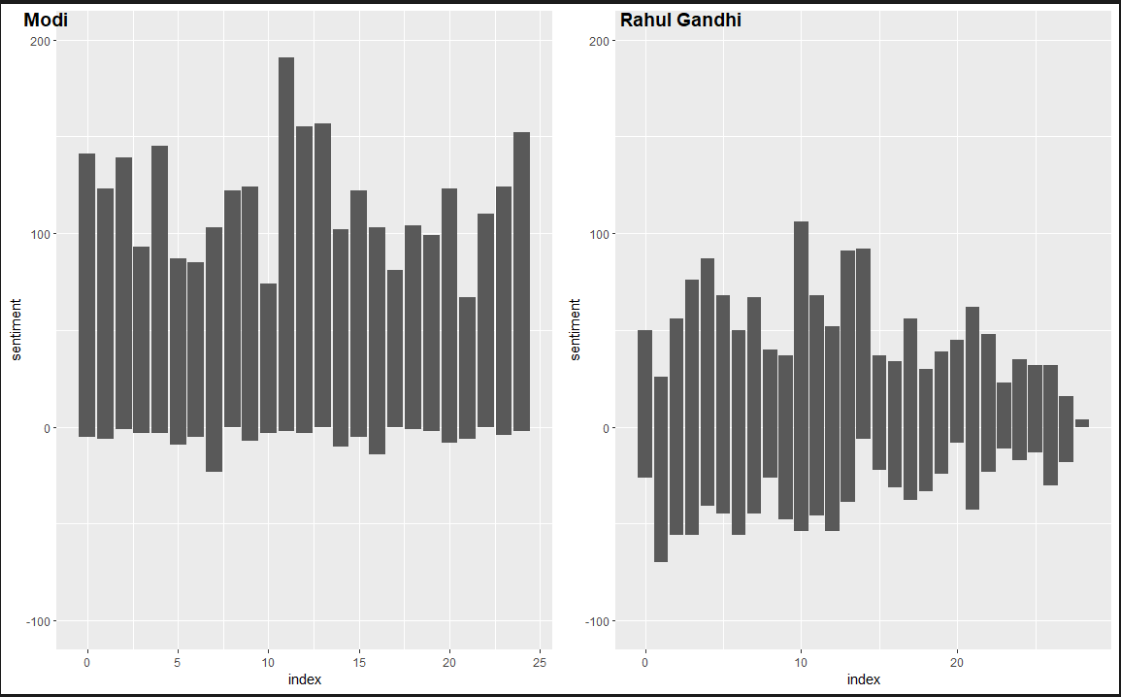 Wow, Modi’s tweets are overwhelmingly positive whilst Rahul Gandhi’s are
a bit more equally distributed between negative and positive. Let’s look
at the stand-out words from amongst them.
Wow, Modi’s tweets are overwhelmingly positive whilst Rahul Gandhi’s are
a bit more equally distributed between negative and positive. Let’s look
at the stand-out words from amongst them.
m<- modi %>%
select(c("X1","tweet")) %>%
group_by(X1) %>%
unnest_tokens(word, tweet) %>%
ungroup() %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup()%>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()
## Joining, by = "word"
## Selecting by n
r<- raga %>%
select(c("X1","tweet")) %>%
group_by(X1) %>%
unnest_tokens(word, tweet) %>%
ungroup() %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
group_by(sentiment) %>%
top_n(10) %>%
ungroup() %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(word, n, fill = sentiment)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment",
x = NULL) +
coord_flip()
## Joining, by = "word"
## Selecting by n
ggarrange(m, r, nrow = 2, labels = c("Modi", "Rahul"))
Classification
Before getting started, let’s quickly take a look at the number of English tweets by the two to gauge class imbalance.
data <- data[data$lang=="en",]
table(data$Person)
##
## Modi Rahul Gandhi
## 1536 1481
Seems okay. Let’s move onto classifying the tweets. Let’s only take the tweet and person who tweeted it.
hm <- as.data.frame(data %>% select(Person, tweet))
hm <- na.omit(hm)
hm$Person <- as.numeric(as.factor(hm$Person))
str(hm)
## 'data.frame': 3017 obs. of 2 variables:
## $ Person: num 1 1 1 1 1 1 1 1 1 1 ...
## $ tweet : chr "NDRF teams are working in the cyclone affected parts. Top officials are closely monitoring the situation and al"| __truncated__ "Have been seeing visuals from West Bengal on the devastation caused by Cyclone Amphan. In this challenging hour"| __truncated__ "My thoughts are with the people of Odisha as the state bravely battles the effects of Cyclone Amphan. Authoriti"| __truncated__ "On his death anniversary, tributes to former PM Shri Rajiv Gandhi." ...
## - attr(*, "na.action")= 'omit' Named int 147 254 279 1033 1034 1035 1042 1095 1096 1160 ...
## ..- attr(*, "names")= chr "147" "254" "279" "1033" ...
Okay, now we should go ahead and split it into testing and training sets. I’ll use the carets package here. Let’s use the XGBoost algorithm to train our model.
library(caret)
## Loading required package: lattice
trainIndex <- createDataPartition(hm$Person, p = .8,
list = FALSE,
times = 1)
train <- hm[trainIndex,]
test <- hm[ -trainIndex,]
In order to build our model, we need to tokenize our data and transform it to Document Term Matrices. Using word tokens here makes sense.
library(text2vec)
get_matrix <- function(text) {
it <- itoken(text, progressbar = TRUE)
create_dtm(it, vectorizer = hash_vectorizer(),c("dgCMatrix"))
}
dtm_train= get_matrix(train$tweet)
dtm_test = get_matrix(test$tweet)
library(xgboost)
##
## Attaching package: 'xgboost'
## The following object is masked from 'package:dplyr':
##
## slice
param <- list(max_depth = 20,
eta = 0.07,
objective = "binary:logistic",
eval_metric = "error",
nthread = 1)
set.seed(1234)
xgb_model <- xgb.train(
param,
xgb.DMatrix(dtm_train, label = train$Person == 1),
nrounds = 100,
verbose=0
)
Let’s check the accuracy of the model. We use a threshold of 0.5
predictions <- predict(xgb_model, dtm_test) > 0.5
test_labels <- test$Person == 1
print(mean(predictions == test_labels))
## [1] 0.8772803
We’re getting about 86% accuracy with this model. Let’s try to see what words our classifier picked up on. Let’s run lime’s explainer.
library(lime)
##
## Attaching package: 'lime'
## The following object is masked from 'package:dplyr':
##
## explain
predictions_tb = predictions %>% as_tibble() %>%
rename_(predict_label = names(.)[1]) %>%
tibble::rownames_to_column()
## Warning: rename_() is deprecated.
## Please use rename() instead
##
## The 'programming' vignette or the tidyeval book can help you
## to program with rename() : https://tidyeval.tidyverse.org
## This warning is displayed once per session.
correct_pred = test %>%
tibble::rownames_to_column() %>%
mutate(test_label = Person == 1) %>%
left_join(predictions_tb) %>%
filter(test_label == predict_label) %>%
pull(tweet) %>%
head(6)
## Joining, by = "rowname"
explainer <- lime(correct_pred, model = xgb_model,
preprocess = get_matrix)
corr_explanation <- lime::explain(correct_pred, explainer, n_labels = 1,
n_features = 6, cols = 2, verbose = 0)
plot_features(corr_explanation)

#plot_text_explanations(corr_explanation)
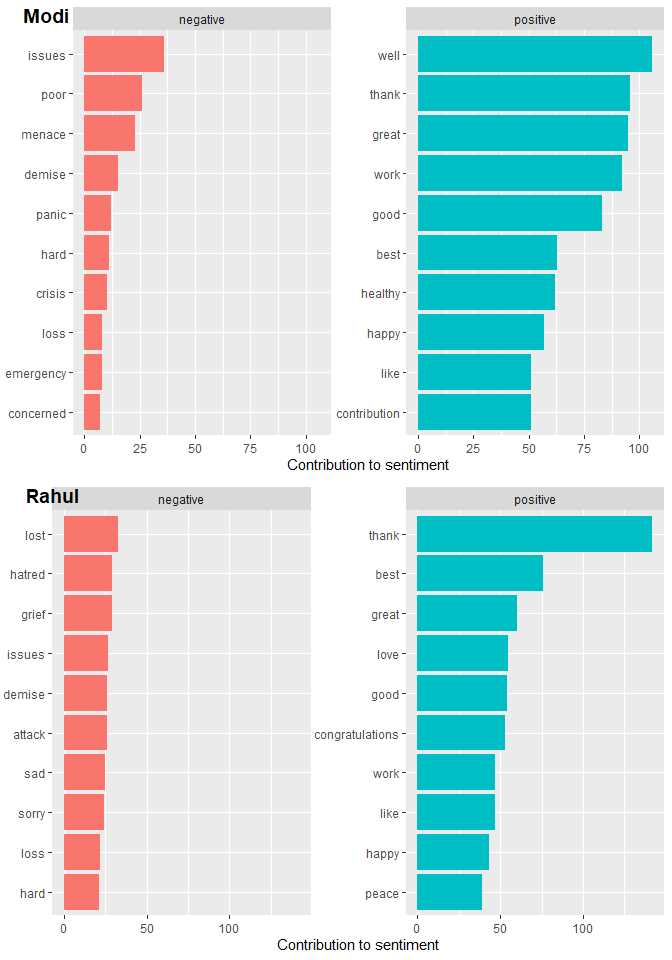
Looks like Modi uses words like “progress” and “ensuring” whereas Rahul Gandhi uses “today” and “space” more.